ASCII
我们熟悉的 ASCII 码可以说是字符编码的始祖了。它规定了常用的数字、符号、英文字母与二进制之间的对应关系。
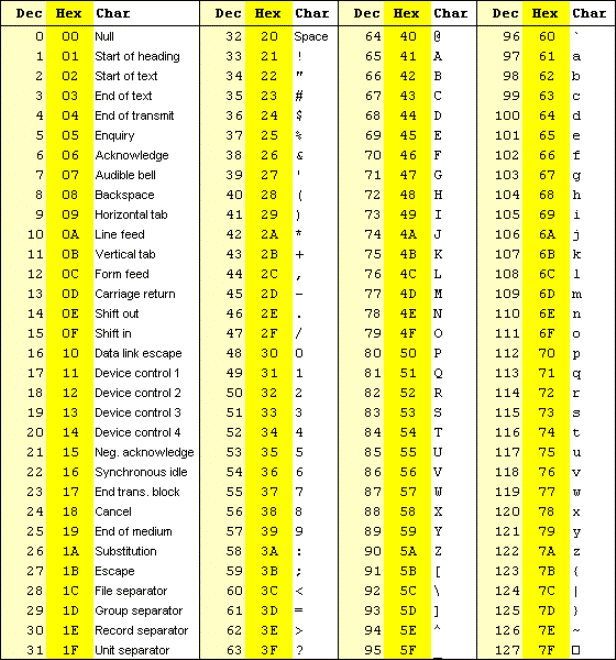
ASCII 的缺点是字符集太少了,只能表示英文和数字,无法表示像中文,日文这样的符号。因此人们就设计出了 Unicode 字符集,囊括了几乎所有人类语言文字的符号。
Unicode
Unicode 是一个字符集,而不是一种编码方式。 Unicode 相当于是给人类所有的符号一个独一无二的 ID,只要大家都是用这个 ID 表示字符,就不会出现乱码的问题。
因为 Unicode 是一个字符集,因此它不存在所谓的 “用几个字节表示 unicode” 这样的问题,这是具体的编码方式需要处理的事。
Unicode 把 ID 划分成了 17 组 (Plane),每组有 65536 个字符,编号可以用 U+[XX]YYYY 这样的形式表示,每一位是一个十六进制数字,其中 XX 代表组编号,从 0 到 0x10,一共17个,YYYY 代表这一组中的字符编号,一共 65536 个。
其中第 0 组叫 Basic Multilingual Plane,简称 BMP,它是 Unicode 中最基础和最常用的一部分,码点范围是U+0000 ~ U+FFFF,包含了我们常用的英文和汉字。
UFT-8
UTF-8 是 Unicode 具体的编码方式,除此之外还要 UTF-16, UTF-32 等等。
为什么需要编码方式呢? 直接用 Unicode 的 ID 不就行了吗? 因为我们需要节省存储空间。
UTF-8 是一种变长的编码方式,它可以使用 1-4 个字节表示一个符号,编码规则如下
- 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,
UTF-8编码和 ASCII 码是相同的。 - 对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下图是一个汉字“诗” 编码成 UTF-8 的例子,图片来自参考资料 1

Python 中的编码
Python 默认使用 utf-8 编码,
>>> sys.getdefaultencoding()
'utf-8'
python 在内存中是直接用 Unicode 来表示字符串的,
>>>
>>> '\u4e2d\u6587'
'中文'
当输入 '\u4e2d\u6587' 后,显示的是它对应的 unicode 字符。
因此,在 python 中,一个字符串无前缀和加上 u 前缀,构造出来的字符串常量是一样的。
>>> s1 = "中文"
>>> s2 = u"中文"
>>> type(s1)
<class 'str'>
>>> type(s2)
<class 'str'>
>>> print(len(s1), len(s2))
2 2
>>> print(s1 == s2)
True
当我们把一个字符串赋值给变量后,需要使用 encode/decode 函数来进行编码和解码
>>> s = "中文"
>>>
>>> s.encode("unicode-escape")
b'\\u4e2d\\u6587'
>>> b'\\u4e2d\\u6587'.decode("unicode-escape")
'中文'
>>> s.encode("utf-8")
b'\xe4\xb8\xad\xe6\x96\x87'
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode("utf-8")
'中文'
注意,可以使用 b 开头的字节串加上 decode 函数来进行解码,如果省略的 b ,无论是 utf8 还是 unicode escape 都会报错。
>>> '\xe4\xb8\xad\xe6\x96\x87'.decode("utf-8")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'str' object has no attribute 'decode'
'\\u4e2d\\u6587'.decode("unicode-escape")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'str' object has no attribute 'decode'
这是因为省略 b 则引号内代表的是字符串,加上 b 代表的是十六进制字节,并且 bytes 只能包含ASCII字符。
>>> x = b'abc'
>>> y = b'你好'
File "<stdin>", line 1
SyntaxError: bytes can only contain ASCII literal characters.