跳表(skiplist) 是一个非常有趣的、简单的数据结构, 应用也非常广泛, 著名的NoSQL内存数据库Redis, 就用到了skiplist作为排序集合的基础数据结构。 跳表最大的特点就是插入、删除操作的性能均为O(logn) 。
关于它的原理网上有一大堆,如果不了解的话,可以先看看文章末尾的参考资料, 或者动手google一下。
需要指出的是,网上搜的一些的文章原理介绍的不错, 但是代码写的有点乱, 排版的时候也没有语法高亮, 所以我自己也参照着写了一份, 并且在这里简单的注释一下。
首先, 一个“跳表” 基本上长的是这个样子的:
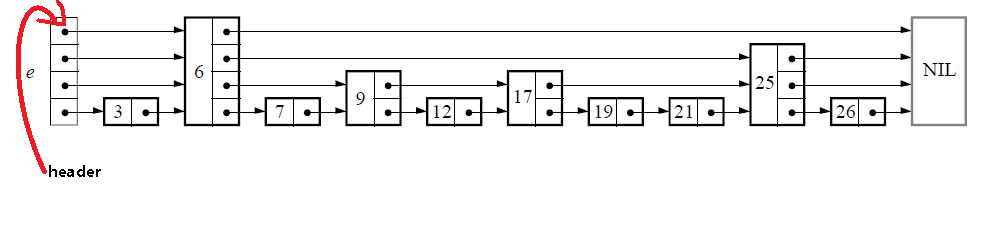
再来看下抽象的数据结构:
#define object int
typedef struct _node {
int key;
object *obj;
struct _node *forward[1];
} node;
typedef struct _skiplist {
int level;
struct _node *head;
} skiplist;
值得注意的是, 结构体 node 的 forward 指针数组长度为1, 而我们从 skiplist 的长相和定义来看, forward 数组大小是随机的, 在 1 – MAX_LEVEL 之间, 因此, 一个技巧就是这样:
node *nd = (node *)malloc(sizeof(node) + level * sizeof(node *));
每次创建新的节点的时候, 都必须用到上面这条语句。
其实, 从数据结构的角度来看,上面这张图并没有很好的表示出整个skiplist结构, 我特地手绘了一个版本,看代码会更容易懂一些。
假设有 21, 32, 14 , 7 37被依次插入到链表中,并且 level 随机生成如图所示,那么按照我的代码一步一步的插入,最后应该是这个样子的。
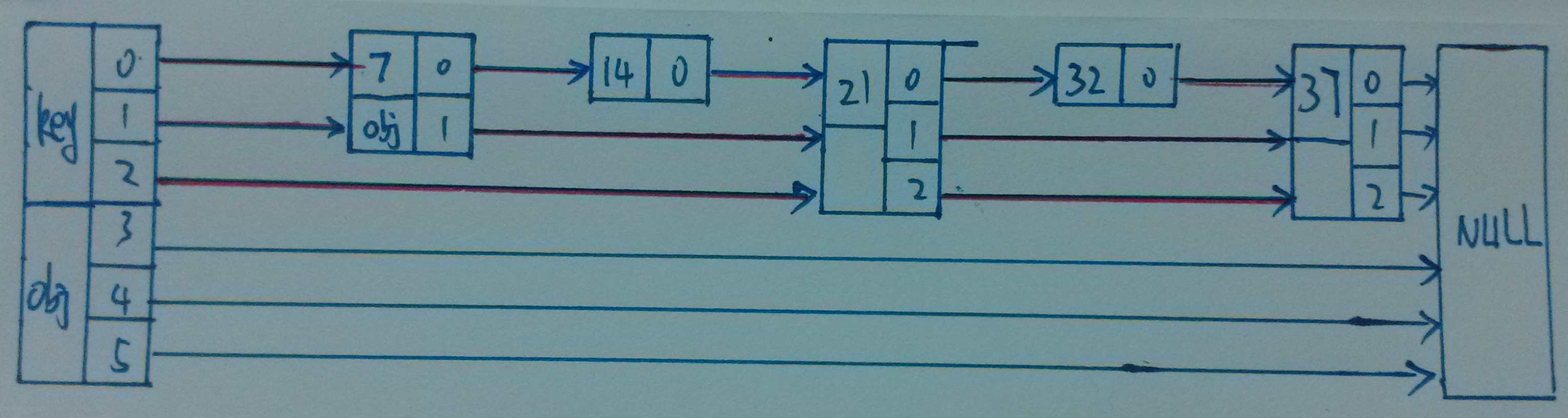
最后附上一个我用 C 语言 写的一个 skiplist
参考资料
- http://en.wikipedia.org/wiki/Skip_list
- http://www.cnblogs.com/xuqiang/archive/2011/05/22/2053516.html
- 如果真的闲的蛋疼的话, 可以拜读一下 William Pugh 的论文,就是他发明了skiplist。