本文介绍如何在 Linux 虚拟机中直接使用 GPU 做科学计算,要达到这个目的,需要满足下面几个条件:
- 物理主机使用 VMWare ESXi 作为虚拟化的 VMM,并且版本最好大于等于 6.5
- 使用的是 Nvidia GPU 的显卡
- Linux 虚拟机 OS 没有限制,我使用的是 ubuntu
ESXi 开启显卡直通
假设已经安装好了 ESXi,通过 WebUI 进入 Host 的 Manage 界面,点击 Hardware,如图

把 nVidia 开头的这几个全部选中,然后 “Active”, 表示开启 PCI 设备的直通 (passthrough)。
重启物理主机。
配置虚拟机
创建一个新虚拟机,或者修改已有的虚拟机,
点击 Edit,VM Options ,在 Advanced 里面点击 Edit configuration 。
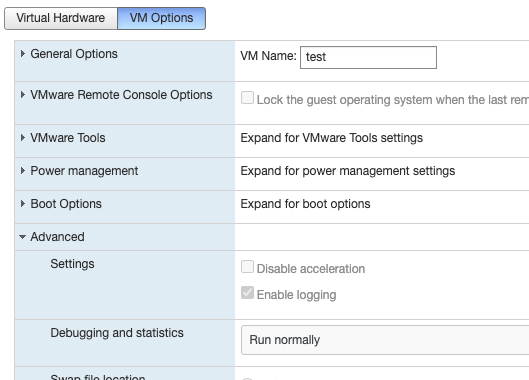
增加一条配置参数 hypervisor.cpuid.v0, 对应的值为 FALSE,这一步的目的是让驱动把虚拟机当做物理机来处理。
另一需要修改的地方让虚拟机硬件配置内存大小下面勾选 “Reserve all guest memory (All locked)”,让虚拟机启动时一次性获取物理主机内存,而不是按需获取。
到这里,主机和虚拟机的配置就全部完成了,接下来是驱动软件的安装
虚拟机安装驱动
重启并进入虚拟机 CLI,首先可以确认一下 GPU 已经被直通给了虚拟机,这一步不是必须要做,但检查一下没坏处。
$ lshw | grep display
$ sudo apt install ubuntu-drivers-common
$ ubuntu-drivers devices
接下来,禁用系统自带的开源 nouveau 驱动
$ sudo apt install gcc g++ make
$ sudo bash -c "echo blacklist nouveau > /etc/modprobe.d/blacklist-nvidia-nouveau.conf"
$ sudo bash -c "echo options nouveau modeset=0 >> /etc/modprobe.d/blacklist-nvidia-nouveau.conf"
$ cat /etc/modprobe.d/blacklist-nvidia-nouveau.conf
然后去 nvidia 官网下载对应的显卡驱动 https://www.nvidia.com/Download/index.aspx
安装驱动
$ chmod +x NVIDIA-Linux-x86_64-440.82.run
$ sudo ./NVIDIA-Linux-x86_64-440.82.run
重启虚拟机之后,运行 nvidia-smi 命令,出现类似如下结果说明安装成功
$ nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.88 Driver Version: 418.88 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 7 TITAN RTX On | 00000000:B2:00.0 Off | N/A |
| 46% 66C P2 215W / 280W | 23509MiB / 24190MiB | 65% Default |
+-------------------------------+----------------------+----------------------+
对比 CPU 和 GPU 的运算速度
安装 docker
sudo apt install apt-transport-https ca-certificates curl software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu bionic stable"
sudo apt update
sudo apt install docker-ce
sudo usermod -aG docker ${USER}
安装 nvidia docker
$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
$ curl -s -L https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
$ sudo apt-get update
$ sudo apt-get install -y nvidia-docker2
$ sudo pkill -SIGHUP dockerd
$ docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi
如果最后一条命令输出结果和之前的 nvidia-smi 一样,则说明在 docker container 可以使用 GPU 计算了。
除了指定 runtime 参数以外,我们也可以直接用 nvidia-docker 命令代替原来的 docker 命令。
拉取 docker image
看到这里,小朋友你们是不是有很多问号? 说好的对比 CPU 和 GPU 速度为什么要安装 docker 呢?
因为我懒得去搭建使用 GPU 做科学计算的各种环境,pull 一个 docker image 是最省力的方法。当然,你们也可以直接在 VM 中安装各种机器学习的 python 包。
首先,pull 一个 TensorFlow image
docker pull gcr.io/kubeflow-images-public/tensorflow-2.1.0-notebook-gpu:1.0.0
然后运行并进入这个 container 的命令行
sudo nvidia-docker run --rm -it -p 8000:8888 -e GRANT_SUDO=yes -u root gcr.io/kubeflow-images-public/tensorflow-2.1.0-notebook-gpu:1.0.0 bash
命令行类似于下面这样
_______ _______________
___ __/__________________________________ ____/__ /________ __
__ / _ _ \_ __ \_ ___/ __ \_ ___/_ /_ __ /_ __ \_ | /| / /
_ / / __/ / / /(__ )/ /_/ / / _ __/ _ / / /_/ /_ |/ |/ /
/_/ \___//_/ /_//____/ \____//_/ /_/ /_/ \____/____/|__/
tf-docker /tf >
最后,直接用 python 运行下面这段代码
import tensorflow as tf
import time
def matmul(device_str):
a = tf.random.normal((20000, 8000))
b = tf.random.normal((8000, 8000))
with tf.device(device_str):
c = tf.matmul(a,b)
return c
g = tf.Graph()
with g.as_default():
cpu_c = matmul("/cpu:0")
gpu_c = matmul("/gpu:0")
init = tf.compat.v1.global_variables_initializer()
with tf.compat.v1.Session(graph=g) as sess:
sess.run(init)
for i in range(50):
print("======== {} =======".format(i))
start = time.time()
sess.run(cpu_c)
end = time.time()
print("cpu time: {}".format(end-start))
start = time.time()
sess.run(gpu_c)
end = time.time()
print("gpu time: {}".format(end-start))
它会打印出 CPU 和 GPU 分别使用了多少时间。
在运行期间,我们也可以看到 python 程序占用了 GPU
$ nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.88 Driver Version: 418.88 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 7 TITAN RTX On | 00000000:B2:00.0 Off | N/A |
| 46% 66C P2 215W / 280W | 23509MiB / 24190MiB | 65% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 7 42352 C python 23499MiB |
+-----------------------------------------------------------------------------+
在我自己的机器上,GPU 比 CPU 快 10 倍左右。
这是因为 GPU 天然适合做矩阵运算,所以耗时会有明显的差异,如果换成其他的计算,结果可能就是 CPU 更快了。
(完)