LSM Tree 是 Log Structured Merge Tree 的缩写,这种 Tree 数据结构的特点就是”Log Structured“ 和 ”Merge“。LSM Tree 主要用在各种新兴的数据库,作为底层数据结构。 提供了比 B+ 树/ISAM 更好的写性能。
本文是一篇读书笔记,作为以后再次阅读的提纲,此外,原文旁征博引有不少参考资料,值得一读。 原文传送门。
Some Background
核心: 硬盘(无论是磁盘,SSD 甚至是内存)随机读写性能太差,但是顺序读写性能非常高,所以要充分利用一点。
这篇文章指出,磁盘的顺序访问甚至比内存的随机访问还快!
所以,如果我们对写性能要求高,怎么办? 一种方法是写数据的时候只 append(添加在文件尾部)。通常我们把这种叫做写日志,logging。
但是,简单的 log 结构无法满足复杂的需求,为了满足类似搜索、kv 之类的场景,需要在 logging 基础上加上额外的数据结构,比如 binary search, hash, B+ or external。
- Search Sorted File: save data to a file, sorted by key. If data has defined widths use Binary search. If not use a page index + scan.
- Hash: split the data into buckets using a hash function, which can later be used to direct reads.
- B+: use navigable file organisation such as a B+ tree, ISAM etc.
- External file: leave the data as a log/heap and create a separate hash or tree index into it.
以上 4 种方法都可以改善读性能。
但是,问题来了, 用各种数据结构(hash index / B+ Tree)的目的是把数据按照一定规律有组织的存放在磁盘上,这样索引和查找的时候速度才快,而这恰恰违反了上文提到了”顺序访问“ 速度才是最快的。所以这是一个悖论。
一个常用的方法是增加一个 index 在内存里。例如,Key-to-Offset mapping,一个 hash table 映射 key 对应的 value 是在 log 中的位置/偏移量。限制是 如果你的数据大小非常小,那么这种方法非常浪费不值得。
所以 LSM tree 解决以上短板:需要在内存中存一个 index,但是规模很小;写性能很高,轻微的影响读性能。最重要的是所有的 disk access 都是顺序的。
A number of tree structures exist which do not require update-in-place. Most popular is the append-only Btree, also know as the copy-on-write tree. These work by overwriting the tree structure, sequentially, at the end of the file each time a write occurs. Relevant parts of the old tree structure, including the top level node, are orphaned. Through this method update-in-place is avoided as the tree sequentially redefines itself over time. This method does however come at the cost: rewriting the structure on every write is verbose. It creates a significant amount of write amplification which is a downside unto itself.
The Base LSM Algorithm
数据首先插入到内存的 buffer ,叫做”memtable“,它实际是一个红黑树,所以数据都是按照 key 有序的。这个 memtable 也会被写到磁盘上,但是只做灾难恢复用途。随着数据的增加,memtable 定时会把有序的数据写到磁盘上的新文件中。写到磁盘上的文件不会被修改,新的数据或者修改都是通过增加新的 memtable 实现的。
旧的文件不会被修改,新的数据会通过 memtable 写到磁盘上,这其中当然也包括了重复的数据或者对已有数据的修改,所以会产生一定的冗余。所以系统会定时压缩,选定多个文件,然后把它们合并到一起,去除冗余。
以上是写操作的过程,当需要读的时候,先检查 memtable,如果找不到在从文件中找,虽然数据都排序了但是这个过程也是很慢的。
所以有几个 tricks 可以提高读的性能。其中一个就是在内存中维护一个 page-index。LevelDB, RocksDB 的方法是在每个文件尾部加一个 block-index 。
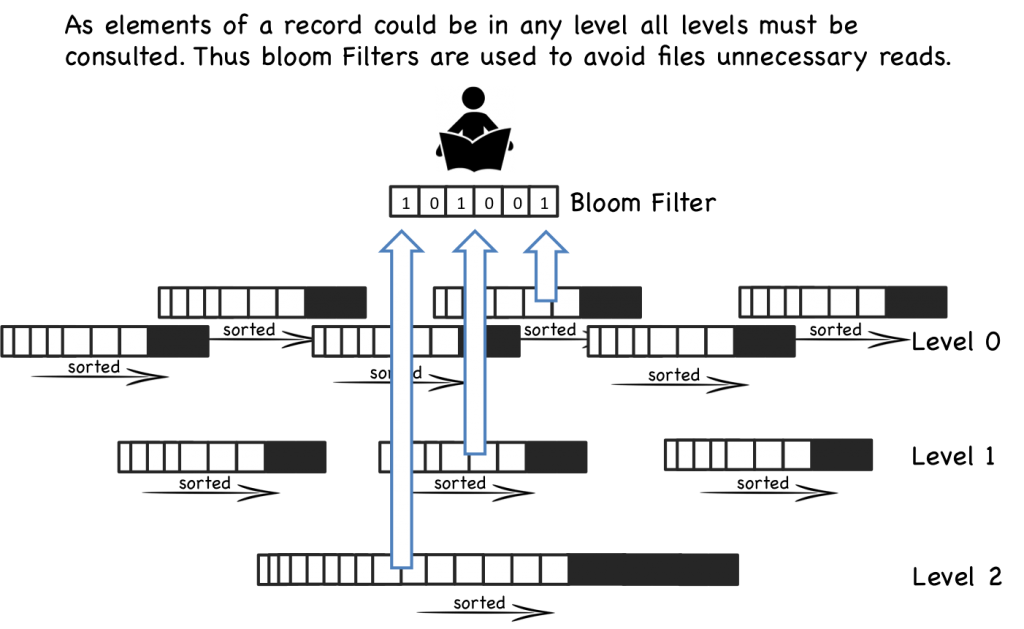
Bloom Filter
但是当 memtable 或者磁盘文件数量非常庞大的时候,即使有 per-file index, 加上合并小文件,也还是很慢。所以很多实现还加上了 Bloom Filter
Basic Compaction
这个过程有点像垃圾回收:当 files 达到一定数量,比如5个文件,每个文件 10 行,就会被合并成一个50行的文件。这个过程继续,直到有 5 个 50 行的文件,然后把这些文件再合并成一个 250 行的文件。
Leveled Compaction
LevelDB,RocksDB 和 Cassandra 使用了一个 level-based 的方法,而不是上面介绍的 size-based 的方法进行压缩。
level-based 方法与 size-based 有两个关键不同:
- 每一层包含一定数量的文件,并且这些文件中的 key 不会重叠。也就是说,key 被 partition 到不同的文件上去了,因此在特定的一层找一个 key 只需要找到一个文件即可。(只有第一层不满足这个性质,key可以存在于多个文件中)
- 每次只把底层的一个文件合并到上一层去。当一层满了的时候,摘取一个文件 merge 到上层,给后续的数据留出空间。这点于 Baisc Compaction不同,它是把多个相同 size 的合并成一个大的。
以上两点不同意味着 level based 方式把压缩产生的影响转嫁到时间复杂度上,同时需要更少的空间。读性能也更好。
Summary
LSM tree 是介于 简单的 log 文件和 复杂的 B+ 树/hash index 之间的一种数据结构。它提供了一种更高效的方法去管理大量的小数据。 LSM tree 写操作比 B+树 / hash index 更加高效,缺点是读操作需要付出更大的代价
Thoughts on the LSM approach
SSTable (memtable)是只读不可修改的,因此对它的加锁操作非常简单,不想其他的 Tree,对于不同 level 的加锁非常复杂。 大内存可以优化读操作的性能。
参考资料
- https://github.com/google/leveldb/blob/master/doc/impl.md
- https://www.datastax.com/dev/blog/leveled-compaction-in-apache-cassandra
- https://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying
- https://queue.acm.org/detail.cfm?id=1563874
- http://www.eecs.harvard.edu/~margo/cs165/papers/gp-lsm.pdf
- http://symas.com/mdb/microbench/
- https://s3-eu-west-1.amazonaws.com/benstopford/nosql-comp.pdf
- http://researcher.ibm.com/researcher/files/us-wtan/DiffIndex-EDBT14-CR.pdf