Background
本文背景是这样的: 有一个线上服务使用了 go-redis 库连接 redis,目前 QPS 也不是很高,大约每秒一次的样子,但是通过 log 发现每次 redis 操作花费的时间如下:
redis call cost: 0 ms
redis call cost: 2 ms
redis call cost: 0 ms
redis call cost: 1 ms
redis call cost: 0 ms
redis call cost: 17 ms
redis call cost: 0 ms
....
正常一个简单的 redis get 操作耗费 0-3ms 时间可以理解,但是为什么会出现 17 ms 呢? 而且出现的频率还不低,大概每 30 个正常的中会出现一个。
尝试 debug
首先总结一下场景和条件
- service 部署在 k8s 中,大概 10 个 pod 在运行。
- 整个 service 的 QPS 大概一秒一个,很低。
- 高延迟的情况大概每 30 个 log 出现一个。
- service 使用简单的 redis get(),没有复杂操作。 但是 service 本身是有很多 go routine 并发的。
所以可能出现问题的地方
- 单个 service 的 go routine 是否产生了竞态条件? 锁的占用 ?
- go-redis 库是不是也有锁的抢占? (这是一个流行的库,不应该出现这么低级的问题)
- 多个 service pod 访问 redis 导致抢占? (应该也不会, redis 本身是支持很高并发的,不会因为 10 个 pod 就变慢)
- k8s 本身网络问题 ?
于是,我写了一个简单的程序,模仿线上 service,也使用了多个 goroutine,希望能至少确定是不是 go-redis的问题,如果自始至终都不会出现 17 ms 这样的高延迟,那么问题出在 service 代码的可能性就很大了。
结果是偶尔能 reproduce 高延迟,但是一直找不到稳定产生这个 bug 的方法。 接下来甚至换成了 redigo 这个库,似乎基本不会出现高延迟了。
难道是 go-redis 本身有问题? 这么多人用没有人发现吗 ? 于是去 github 搜索了一圈,好像也没有人提这个问题,难道大家都对十几毫秒的高延迟不在乎?
pprof
既然没什么思路,那就用 pprof 试试。 尝试抓了几次 pprof,每次的函数调用栈都有差别,不完全一样,这也让我比较疑惑:该用哪个结果呢?
放上一个还算比较多的 h1.pprof
光看这个图也无法确定哪个地方有问题,而且高延迟在整个采样中可能正好发生了,也可能没发生。
既然有了 pprof,当然也要顺便看下火焰图
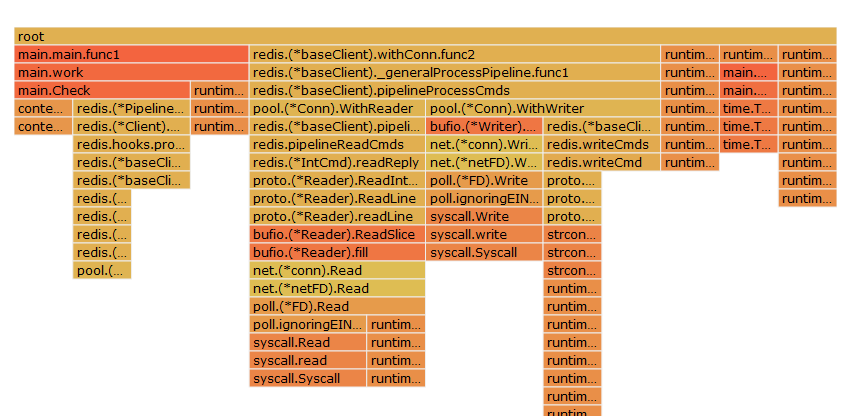
y 轴表示调用栈,每一层都是一个函数。调用栈越深,火焰就越高,顶部就是本次采样时正在执行的函数,下方都是它的父函数。
x 轴表示抽样数,如果一个函数在 x 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长,说明它是瓶颈原因的可能性就越大。注意,x 轴不代表时间,而是所有的调用栈合并后,按字母顺序排列的。
火焰图就是看顶层的哪个函数占据的宽度最大。只要有"平顶"(plateaus),就表示该函数可能存在性能问题。
用 service 代码 debug
既然用简单测试程序没有太多思路,就试试直接在 dev 环境 debug 了。
前面提到了条件: 10 个 pod,QPS 一秒一个,大概 30 多个出现一次。
于是我用 k6 工具模拟 gRPC request,并设定发送 request 频率为一秒一个,果然,在 dev 环境能出现这个问题。
然后用 copy 我的测试程序到 Pod 里面,只运行一次,只调用一个 redis get,发现用了十几毫秒,但这是合理的,因为初次启动程序要建立 tcp,所以耗费时间多一些。
接着,我想到了上面的 pprof 图,其中如下一个调用关系
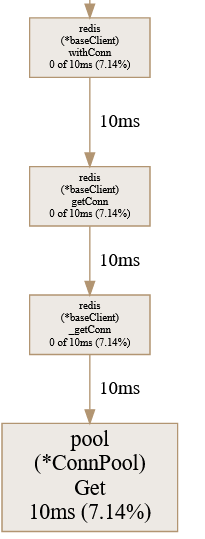
这时我想到,这个高延时也是17 ms,与TCP 建立耗时差不多,那么是不是 go-redis 没有管理好自己的 connection pool,新建 TCP 连接导致的 ?
带着这个设想,我回忆了下 conn pool 的管理方式,去年这个时候也写过一篇 如何设计一个连接池
然后在 Get 函数的 netConn 调用前后打印出时间,并用 go mod vendor 的方式编译代码。
func (p *ConnPool) Get(ctx context.Context) (*Conn, error) {
for {
p.connsMu.Lock()
cn, err := p.popIdle()
p.connsMu.Unlock()
if err != nil {
return nil, err
}
if cn == nil {
break
}
if p.isStaleConn(cn) {
_ = p.CloseConn(cn)
continue
}
atomic.AddUint32(&p.stats.Hits, 1)
return cn, nil
}
atomic.AddUint32(&p.stats.Misses, 1)
newcn, err := p.newConn(ctx, true)
return newcn, nil
}
结果验证了我的猜想,于是 root cause 清楚了。
go-redis 默认会每隔 5 分钟清理一下 idle 的连接,正由于线上服务 QPS 不高,而且有 10 个 Pod 提供服务,更加增大了某个 TCP 连接在 5 分钟内没有 redis 操作的可能性,因此会被断开,而下次有个 request 过来的时候,就需要重建 TCP,导致这个 request 耗时特别长。
解决方法就是 NewClient() 的时候 disable 这个清理 idelConn 的功能,或者维护一个 idle TCP 连接
// Minimum number of idle connections which is useful when establishing
// new connection is slow.
MinIdleConns int
// Amount of time after which client closes idle connections.
// Should be less than server's timeout.
// Default is 5 minutes. -1 disables idle timeout check.
IdleTimeout time.Duration
// Frequency of idle checks made by idle connections reaper.
// Default is 1 minute. -1 disables idle connections reaper,
// but idle connections are still discarded by the client
// if IdleTimeout is set.
IdleCheckFrequency time.Duration
总结
go pprof 是基于采样的,有的时候并不能抓到发生问题时刻的各种函数调用,特别是像本文的情况:绝大部分时间正常,偶尔会跳出一个 latency 特别高,那么很可能就导致 pprof 的结果没什么用。 解决思路就是多抓几次,并且对每次的结果中的函数都思考思考,有时候有 bug 的函数可能会出现在 pprof 中,但是并不是最显眼、最红的那个。
另外,这篇文章中的 debug 方法值得学习 https://www.jianshu.com/p/dc1d6af84b39
特别是其中 go pprof kubelet 的方法
# kubectl proxy --address='0.0.0.0' --accept-hosts='^*$'
# docker run -d --name golang-env --net host golang:latest sleep 3600
# go tool pprof -seconds=60 -raw -output=kubelet.pprof http://APIserver:8001/api/v1/nodes/node_name/proxy/debug/pprof/profile
# ./stackcollapse-go.pl go_kubelet.pprof > go_kubelet.out
# ./flamegraph.pl go_kubelet.out > go_kubelet.svg
还有这篇文章也值得一看,go-redis 和 redis server 版本错位导致的高延时问题一例