etcd-raft 有关 log 的实现在分布在log.go,log_unstable.go,storage.go 三个文件中。首先看一下 raftLog 结构体。
raftLog 结构体
type raftLog struct {
// storage contains all stable entries since the last snapshot.
storage Storage
// unstable contains all unstable entries and snapshot.
// they will be saved into storage.
unstable unstable
// committed is the highest log position that is known to be in
// stable storage on a quorum of nodes.
committed uint64
// applied is the highest log position that the application has
// been instructed to apply to its state machine.
// Invariant: applied <= committed
applied uint64
}
- 其中 Storage 存放 stable 的 log,它是一个接口,具体实现可由应用层控制,在 raftexample 和 etcd server 中都是用了 默认的实现
MemoryStorage - unstable 存放的是还未放到 stable 中的 log,可见实际上无论是 stable 还是 unstable,他们都是存在内存中的,那么不怕断点导致的丢失吗? 其实真正生产环境中使用的 etcd server 在写入 MemoryStorage 前还要写入 WAL 和 snapshot,也就是说,etcd的稳定存储是通过快照、预写日志、MemoryStorage 三者共同实现的。具体细节本文先不讨论。
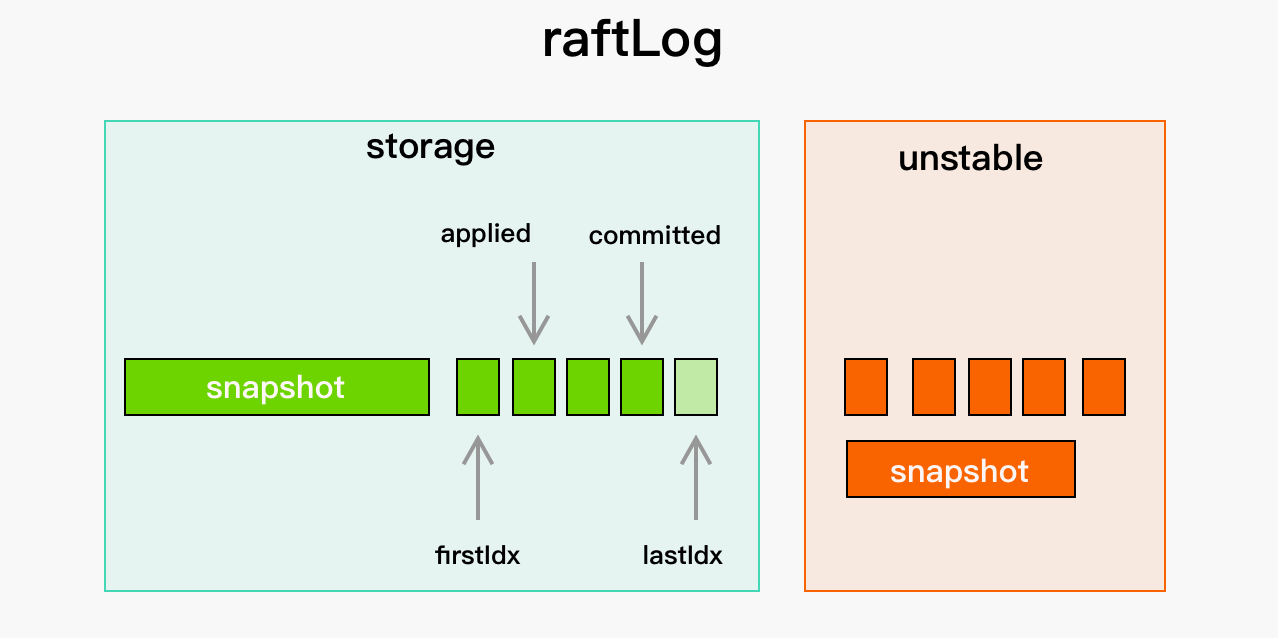
- committed 表示该节点所知数量达到quorum的节点保存到了 stable 中的日志里,index最高的日志的index
- applied 表示该节点的应用程序已应用到其状态机的日志里,index最高的日志的index。
由此可见,committed 和 applied 都是在 stable 中,不在 unstable。 他们的关系如下所示

因此,applied <= committed 这个不等式关系永远成立。
对应到 raft 论文里,就是 lastApplied <= commitIndex
如何理解这层关系呢? 在网上找到了下面的解释
master收到log后首先store到本地,之后并发发给其他slave;当master收到集群中一半以上的节点确认已经把该log持久化之后,他就会把这条日志commit,然后进行第二阶段:把这个commitindex发送给其他的slave节点。此时这些slave才可以把这条日志apply到你的状态机。
commit了不一定apply了。举个例子:commitIndex为10,lastAppliedIndex为10,这个时候新的commitIndex出来了,比如说15,这个时候你需要应用11~15的log到状态机中,应用完毕之后lastAppliedIndex就变为15。
几个重要的函数
先看一个 raft node 刚启动时如何初始化 raftLog 结构的
func newLogWithSize(storage Storage, logger Logger, maxNextEntsSize uint64) *raftLog {
log := &raftLog{
storage: storage,
logger: logger,
maxNextEntsSize: maxNextEntsSize,
}
firstIndex, err := storage.FirstIndex()
lastIndex, err := storage.LastIndex()
log.unstable.offset = lastIndex + 1
// Initialize our committed and applied pointers to the time of the last compaction.
log.committed = firstIndex - 1
log.applied = firstIndex - 1
return log
}

也就是说,初始状态如上图所示。
func (l *raftLog) firstIndex() uint64 {
if i, ok := l.unstable.maybeFirstIndex(); ok {
return i
}
index, err := l.storage.FirstIndex()
return index
}
func (l *raftLog) lastIndex() uint64 {
if i, ok := l.unstable.maybeLastIndex(); ok {
return i
}
i, err := l.storage.LastIndex()
return i
}
从上面两个函数可以看出,要想拿到 raftLog 的 first index 或者 last index,先要从 unstable 结构中拿,如果unstable 中没有,再去 storage 中拿。
unstable 结构体
上文提到,要想拿 raftLog 的 first index 或者 last index,先要从 unstable 结构中拿,那就来看下l.unstable.maybeFirstIndex()是如何实现的。
func (u *unstable) maybeFirstIndex() (uint64, bool) {
if u.snapshot != nil {
return u.snapshot.Metadata.Index + 1, true
}
return 0, false
}
func (u *unstable) maybeLastIndex() (uint64, bool) {
if l := len(u.entries); l != 0 {
return u.offset + uint64(l) - 1, true
}
if u.snapshot != nil {
return u.snapshot.Metadata.Index, true
}
return 0, false
}
通过上面的代码不难看出,只有 unstable 中包含快照时,才可能得知整个raftLog的first index的位置(快照前的日志不会影响快照后的状态);而只有当unstable中既没有日志也没有快照时,unstable才无法得知last index的位置。
这里为什么要牵涉到 snapshot 呢?
Snapshot 的来源
在理解为什么 maybeFirstIndex()需要 snapshot 之前,先来看下论文中的一张截图。
unstable log中的 snapshot 来自于 Leader 节点的SnapMsg消息,即 unstable log中的snapshot是被动接收和存储的。
unstable log中的snapshot唯一来源是Leader节点的消息同步,因此,该snapshot需要被转交给应用,由应用完成重放后再删除。
storage的snapshot来源有两种:
- 第一,来自于节点自身生成的snapshot,如果是这样,那么该节点的应用肯定已经包含了snapshot状态,因此,该snapshot无需在应用的状态机中进行重放,其主要目的是进行日志压缩;
- 第二,Leader节点的SnapMsg会将snapshot复制到Follower的unstable log中,进而通知到Follower的应用层,再进一步将其应用到storage。这个snapshot的主要目的是将Leader的应用状态复制到当前的Follower节点,同时相比于日志复制,它减少了数据同步的网络和IO消耗。
有了这些信息以后,我们再来看一下 unstable.maybeFirstIndex()
func (u *unstable) maybeFirstIndex() (uint64, bool) {
if u.snapshot != nil {
return u.snapshot.Metadata.Index + 1, true
}
return 0, false
}
所以,当一个节点存在 unstable.snapshot 时,说明他收到了来自 Leader 的 snapshot 信息,只是还没用通过 Ready 结构体通知上层应用,把它写入到 stable Storage 而已。
那么,为什么获取 first index 只看 snapshot 忽略 entries ,而获取 last index 却先看 entries,再找 snapshot 呢?
在参考资料 4 我找到一种解释:在 unstable 结构中, snapshot 和 entries 逻辑上是一前一后的
------------------- ----------
| snapshot | | entries |
------------------- ----------
这两个部分,并不同时存在,同一时间只有一个部分存在。其中,快照数据仅当当前节点在接收从leader发送过来的快照数据时存在,在接收快照数据的时候,entries数组中是没有数据的;除了这种情况之外,就只会存在entries数组的数据了。因此,当接收完毕快照数据进入正常的接收日志流程时,快照数据将被置空
- maybeFirstIndex:返回unstable数据的第一条数据索引。因为只有快照数据在最前面,因此这个函数只有当快照数据存在的时候才能拿到第一条数据索引,其他的情况只能去 stable storage 拿。
- maybeLastIndex:返回最后一条数据的索引。因为是entries数据在后,而快照数据在前,所以取最后一条数据索引是从entries开始查,查不到的情况下才查快照数据。