限流算法
通常有下面4种:
- 固定时间窗口(计数器)算法
- 基本思想是:在固定时间窗口内对请求数进行统计,然后与阈值比较确定是否进行限流,一旦到了时间临界点,就将计数器清零
- 缺陷: 可能存在在某个时间窗口前90%时间里没有请求,所有的请求都集中在最后10%,这个在该算法中是允许的
- 滑动时间窗口算法
- 基本思想是:一个较大的时间窗口内细分成多个小窗口,大窗口按照时间顺序每次向后移动一个小窗口,并保证每次大窗口内的请求总数不超过阈值。
- 缺陷:滑动窗口是对固定窗口算法的一种改进,但是并没有真正解决固定窗口的临界突发瞬时大流量问题。
- 漏桶算法 Leaky Bucket
- 基本思想是:漏桶算法通过一个固定容量的桶,控制进入桶中的请求总数,然后以一定速率从桶中取出请求进行处理,如果桶已经满了,则直接丢弃请求。
- 缺陷: 漏桶算法因为是先进先出队列,在突发瞬时大流量情况下,会出现大量请求失败情况,不适合抢购,热点事件等场景
- 适用场景:就像漏斗一样,出口处的速率是恒定的。因此漏桶算法是流量最均衡的限流算法,用于对流量进行整型,保证流量以固定的速率进入系统。
- 令牌桶算法
- 基本思想是:令牌桶相当于反向漏桶算法,即以固定速率生成令牌放入固定容量的桶中,每个请求从桶中获取到令牌就允许执行,没有获取到就丢弃。
- 令牌桶算法弥补了漏桶算法无法应对突发大流量问题,即可以针对突发大流量进行限流。
单机 ratelimit
参考资料 1 里面有上面四种算法的实现,这里仅列举一下固定窗口法和漏桶算法。
固定窗口算法
type FixedWindowRateLimiter struct {
threshold int // 阈值
stime time.Time // 开始时间
interval time.Duration // 时间窗口
counter int // 当前计数
lock sync.Mutex
}
func NewFixedWindowRateLimiter(threshold int, interval time.Duration) *FixedWindowRateLimiter {
return &FixedWindowRateLimiter{
threshold: threshold,
stime: time.Now(),
interval: interval,
counter: threshold - 1, // 让其处于下一个时间窗口开始的时间临界点
}
}
func (l *FixedWindowRateLimiter) Allow() bool {
l.lock.Lock()
defer l.lock.Unlock()
// 判断收到请求数是否达到阈值
if l.counter == l.threshold-1 {
now := time.Now()
// 达到阈值后,判断是否是请求窗口内
if now.Sub(l.stime) >= l.interval {
// 重新计数
l.Reset()
return true
}
// 丢弃多余的请求
return false
} else {
l.counter++
return true
}
}
func (l *FixedWindowRateLimiter) Reset() {
l.counter = 0
l.stime = time.Now()
}
漏桶算法
type LeakyBucketRateLimiter struct {
capacity float64 `json:"capacity"` // 桶的容量
water float64 `json:"water"` // 当前桶中水量
flowRate float64 `json:"flowRate"` // 每秒漏桶流速
lastLeakMs int64 `json:"lastLeakMs"` // 上次漏水毫秒数
lock sync.Mutex
}
func NewLeakyBucketRateLimiter(flowRate, capacity float64) *LeakyBucketRateLimiter {
return &LeakyBucketRateLimiter{
capacity: capacity,
flowRate: flowRate,
water: capacity + 1, // 设置起始边界
lastLeakMs: time.Now().UnixNano() / 1e6,
}
}
func (l *LeakyBucketRateLimiter) Allow() bool {
l.lock.Lock()
defer l.lock.Unlock()
// 获取当前时间
now := time.Now().UnixNano() / 1e6
// 计算这段时间流出的水量:
outflowWater := (float64(now - l.lastLeakMs)) * l.flowRate / 1000
// 计算水量: 桶的当前水量 - 流出的水量
l.water = math.Max(0, l.water-outflowWater)
l.lastLeakMs = now
if l.water < l.capacity {
// 当前水量 小于 桶容量,允许通过
l.water++
return true
} else {
// 当前水量 不小于 桶容量,不允许通过
return false
}
}
分布式 ratelimit
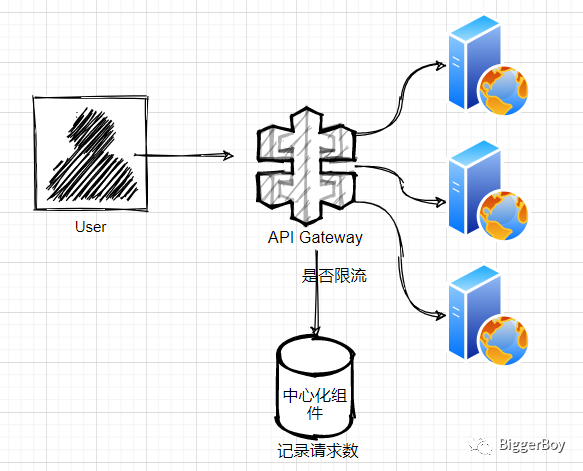
与单机相比,分布式系统(微服务系统)中,即便是 API Gateway 也是有多个副本的,比如 k8s 多个 Pod,那么就需要一个中心化的组件(比如 Redis)来记录请求并判断是否超过限额。
配置在中心化数据库
由于我们想要一个全局的限流器,也就是说服务虽然部署在分布式系统中,但在外界看起来就像部署在单台机器上一样,那样就必须要一个中心化的存储设备去管理限流器,比如Redis。
一种直观的做法是,将限流器配置在数据库中,每个节点收到来自上游的请求后直接请求数据库,然后数据库根据限流器判断是否处理这个请求,最后返回给节点相关信息。如果用Redis实现,限流器的代码可以通过Lua脚本的方式放在Redis端,从而减少节点访问Redis的次数。
但如果服务的流量很大,这种方法则会有很大的成本和性能问题,并且为了得到正确的结果,每个节点访问数据库的时候还需要避免数据竞争,如果是支持事物的数据库还好,如果基于Redis做,这就需要对限流器加锁,Redis的延迟会更高,这样会导致服务处理请求的延迟很高。
Redis + Lua 脚本
一种可行的方案是 Redis + Lua 脚本
- 减少网络开销:使用Lua脚本,无需向Redis 发送多次请求,执行一次即可,减少网络传输
- 原子操作:Redis 将整个Lua脚本作为一个命令执行,原子,无需担心并发
- 复用:Lua脚本一旦执行,会永久保存 Redis 中,,其他客户端可复用
固定窗口(计数法)的 Lua 脚本
-- 计数器限流
-- 此处支持的最小单位时间是秒, 若将 expire 改成 pexpire 则可支持毫秒粒度.
-- KEYS[1] string 限流的key
-- ARGV[1] int 限流数
-- ARGV[2] int 单位时间(秒)
local cnt = tonumber(redis.call("incr", KEYS[1]))
if (cnt == 1) then
-- cnt 值为1说明之前不存在该值, 因此需要设置其过期时间
redis.call("expire", KEYS[1], tonumber(ARGV[2]))
elseif (cnt > tonumber(ARGV[1])) then
return -1
end
return cnt
令牌桶 Lua 脚本
-- 令牌桶限流: 不支持预消费, 初始桶是满的
-- KEYS[1] string 限流的key
-- ARGV[1] int 桶最大容量
-- ARGV[2] int 每次添加令牌数
-- ARGV[3] int 令牌添加间隔(秒)
-- ARGV[4] int 当前时间戳
local bucket_capacity = tonumber(ARGV[1])
local add_token = tonumber(ARGV[2])
local add_interval = tonumber(ARGV[3])
local now = tonumber(ARGV[4])
-- 保存上一次更新桶的时间的key
local LAST_TIME_KEY = KEYS[1].."_time";
-- 获取当前桶中令牌数
local token_cnt = redis.call("get", KEYS[1])
-- 桶完全恢复需要的最大时长
local reset_time = math.ceil(bucket_capacity / add_token) * add_interval;
if token_cnt then -- 令牌桶存在
-- 上一次更新桶的时间
local last_time = redis.call('get', LAST_TIME_KEY)
-- 恢复倍数
local multiple = math.floor((now - last_time) / add_interval)
-- 恢复令牌数
local recovery_cnt = multiple * add_token
-- 确保不超过桶容量
local token_cnt = math.min(bucket_capacity, token_cnt + recovery_cnt) - 1
if token_cnt < 0 then
return -1;
end
-- 重新设置过期时间, 避免key过期
redis.call('set', KEYS[1], token_cnt, 'EX', reset_time)
redis.call('set', LAST_TIME_KEY, last_time + multiple * add_interval, 'EX', reset_time)
return token_cnt
else -- 令牌桶不存在
token_cnt = bucket_capacity - 1
-- 设置过期时间避免key一直存在
redis.call('set', KEYS[1], token_cnt, 'EX', reset_time);
redis.call('set', LAST_TIME_KEY, now, 'EX', reset_time + 1);
return token_cnt
end
优化中心化数据库的限流器
为了解决因为对中心化数据库访问过于频繁并且需要加锁导致的延迟问题,做分布式限流器就必须要减少节点访问Redis的频次。这里我们就可以在节点上做一部分限流器的工作,再周期性地访问数据库同步,以达到减少对数据库请求的目的。以下称中心化数据库上的限流器为中心限流器,每个节点上的限流器为本地限流器。
第一种方法
在节点上积攒够一定的请求量N后再去请求中心限流器,这样节点对中心化数据库的请求频次会降低为1/N。但在请求积攒阶段这些请求就无法决定是否被处理,这样也会造成一定的延迟增加。并且如果请求十分不均匀,在积攒阶段迟迟攒不到N个,即使设置了积攒超时也会大大增加延迟。同时,由于是一次性发送N个请求,也会造成一定的误差。
第二种方法
认为负载均衡器会将流量十分均匀的分布在各个节点上,这样本地限流器的配置就等于全局限流器的配置除以节点数量。这样不需要中心限流器,只需要用一个中心化的数据库比如etcd/Redis存储节点的数量,每个节点以固定的频率请求节点数量更新本地的配置即可。每个节点可以定时向中心化数据库发送心跳,以便中心化数据库可以统计出活着的节点数。这样做对中心化数据库的压力更小,但误差也更大。首先负载均衡器并不能保证流量会十分均匀地打到各个节点上,其次中心化数据库也可能对活着的节点数量统计不准确,因为有可能节点在两次发送心跳图中就挂了。但个人觉得这个误差会始终在容忍范围内。
前两种方法对于令牌桶和滑动窗口都适用,还有一种针对于令牌桶的方法:每个节点初始时请求中心限流器N个令牌,当N个令牌都消耗完了再去数据库请求N个。这种方法和第一种方法比较类似,也会有误差,但相比之下延迟会有所降低。
以上三种方法都会有一定的误差,就目前搜集到的资料来看,笔者没有发现没有误差且成本和性能都能接收的分布式限流器设计。如果是像G公司那样要靠限流来精准定价收费,可能他们就算建分布式数据库做中心化限流器也要准确地计算出TPS。如果是公司内部两个服务之间搞搞,那以上三种方法皆可,个人比较倾向于第二种方法,因为第二种方法对中心化数据库的压力最小,逻辑也比较简单,这样实现成本最小,误差虽然是最大的但感觉也在可容忍范围内。
其他
- 如果客户端也能控制,比如 App,那么在客户端也做限流能减少服务端压力。
- go-redis 库也提供了一个 Redis + Lua 的实现 https://github.com/go-redis/redis_rate/tree/v9