- table {:toc}
问题的表面现象
问题的背景是这样的:
一个应用程序监听某端口的 UDP 包,发送者发送的 UDP 包比较大,有 65535 个字节。显然,发送者的 UDP 包在经过 IP 层时,会被拆分层多个 1460 字节长度的 IP 分片,经过网络传输之后到达接收方,接收方的网卡收到包后,在内核协议栈的 IP 层又将分片重新组合,生成大的 UDP 包给应用程序。
正常情况下,应用程序能准确无误的收到大 UDP 包,偶尔系统网络流量十分巨大的时候,会丢个别 UDP 包 ——这都在允许范围内。
突然有一天,即便网络流量不是很大的时候,UDP 包的丢包十分严重,应用程序几乎收不到任何数据包。
开始 debug
遇到这样的问题,第一反应有两种可能:
- 网络不通,数据包没送到网卡。
- 个别 IP 分片在传输中丢失了,导致接收方无法重组成完整的 UDP 包。
于是用 tcpdump 在 interface eth0 上抓包,出乎意料的是,抓到的 pcap 有完整的 IP 分片。用 wireshark 打开 pcap,wireshark 会自动把 IP 分片重组成 UDP 数据包,检查这个 UDP 包,数据完整无误。
那么现在能断定是应用程序自己出了问题吗?
因为一直以来一个根深蒂固的想法是:既然抓到的 pcap 准确无误,所以数据包已经送到了接收方了,linux 内核只要把分片重组一下交给应用层就可以了,这个过程一般不会出错,所以应用程序没收到只能怪它自己咯?
实际导致问题的原因
最终查明的原因是这台 linux 系统上有两个参数被修改了,当 IP 分片数量过大时,内核中分配给重组的缓冲区已满,导致之后的分片都被丢弃了。
因为 CVE-2018-5390 和 CVE-2018-5391,黑客可以用带有随机偏移量的 IP 分片引发 DoS 攻击(详细见参考资料 1)
RedHat 给无法立刻升级内核的用户的临时解决方案是,减小 net.ipv4.ipfrag_high_thresh 的值,从 4MB 减小到 256 KB;net.ipv4.ipfrag_low_thresh, 从 3MB 到 192 KB。
因为值改动的比较大,所以一些潜在的问题就暴露了出来。
可以用 netstat -s 命令输出一些统计信息,其中 IP Fragment 相关字段会有明显的增长。
本文的标题《tcpdump 抓到的包可信吗?》 似乎有一些标题党,其实在这里我想表达的意思是:能否根据 tcpdump 抓到的 pcap 文件判断一个数据包是否被接收方收到,或者是否被应用程序收到? 之前我想当然的会回答 “是”,现在看来答案是 “否”。
其实平时在使用 tcpdump 时,命令行的输出已经提示了我们有多少包被 kernel 丢弃了:
# tcpdump -ieth0 -s0 -wt.pcap
tcpdump: listening on wlp3s0, link-type EN10MB (Ethernet), capture size 262144 bytes
^C2 packets captured
4 packets received by filter
0 packets dropped by kernel
重新认识 tcpdump
现在回过头来再思考 tcpdump 和内核协议栈的关系。很显然,之前我的理解是错误的,现在根据看到的现象猜测内部实现,那么 tcpdump 的抓包应该是从驱动直接拷贝的,与内核的 TCP/IP 协议栈是完全独立的。
在上网搜索了一些资料后,证实了我的想法。首先来看一张架构图:
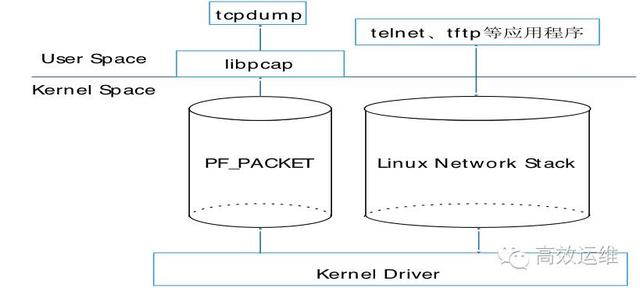
libpcap 使用的是一种称为设备层的包接口(packet interface on device level)的技术。 使用这种技术,应用程序可以直接读写内核驱动层面的数据,而不经过完整的 Linux 网络协议栈。所以抓包大致是这样工作的:
- 网卡加载初始化驱动;
- 报文通过网络到达网卡;
- DMA 将报文复制到内核内存(Ring Buffer)中;
- 复制完毕后,网卡产生硬中断通知系统;
- NAPI 处理内核报文;
- libpcap 将获取的原始报文复制一份;
- 使用设置的过滤器对报文进行过滤,并保存至缓存中;
- 应用程序(Tcpdump、Wireshark)读取缓存中的数据。
PF_PACKET 和 PF_RING
抓包会影响系统的网络性能吗? 当然会。
可以做一个非常简单的实验证明这一点:
- 局域网内 wget 下载一个 500MB 大文件,记录下载速度。
- 局域网内 wget 下载同一个文件,开启 tcpdump 抓包,记录下载速度。
在我的测试中,两者差别是很明显的。
所以,当你的系统下载速度已经达到 50MB/s,你觉得不够,应该至少 100MB/s,这个时候开启 tcpdump 企图抓包分析原因是错误的,因为 tcpdump 本身会影响你的网络性能。
再次回到上面的 tcpdump 架构图,可以看出在内核层使用的是 PF_PACKET,而现在 linux 已经自带了更加先进的 PF_RING 专门针对大流量的场景。有关 PF_RING 下次写一篇博客介绍一下。
tcpdump 与 iptables
首先,tcpdump 直接从网络驱动层面抓取输入的数据,不经过任何 Linux 网络协议栈,
iptables 依赖 netfilter 模块,后者工作在 Linux 网络协议栈中;
iptables 的入栈的策略不会影响到 tcpdump 抓取;而 iptables 的出栈策略会影响数据包发送到网络驱动层面,因此,出栈策略会影响到 tcpdump 的抓取。
总结下来就是:
- tcpdump 可以抓取到被 iptables 在 INPUT 链上 DROP 掉的数据包;
- tcpdump 不能抓取到被 iptables 在 OUTPUT 链上 DROP 掉的数据包