ByteGraph
ByteGraph 是字节跳动开发的一个分布式图数据库。之前只是听说过图数据库,但并没有用过,因此在阅读的过程中难免对一些概念理解的不够深入。
为什么字节要开发图数据库呢?因为字节的产品都是社交App,因此用户,短视频,专注,点赞,粉丝所有的这些构成了一个巨大的图。
为什么现有的数据库无法满足呢? 关系型数据库和文档型数据库显然不适合这样的应用场景,比如要获取两个用户之间的关系,即图中两个节点之间的路径,这个路径可以是关注,可以是都点赞了某个视频,关系型数据库无法满足性能需求。其他的图数据库有的是单机,有的是单 master,都不满足要求,因此需要造轮子。
字节的 Workload 分成了 3 种,比我平时听说的多了一种
- OLTP,在线处理,比如一个用户发布了新文章,那么 (user,article),(user,tag), (article,tag) 这三条边就要被插入数据库。
- OLAP,在线分析数据,一次需要查询大量数据做分析,比如做风险管理分析。
- OLSP,这个第一次听说,Online Serving Processing。比如一个用户点赞了某个视频,那么后台需要实时计算他的喜好,然后推荐类似的视频。
整体架构如下所示:
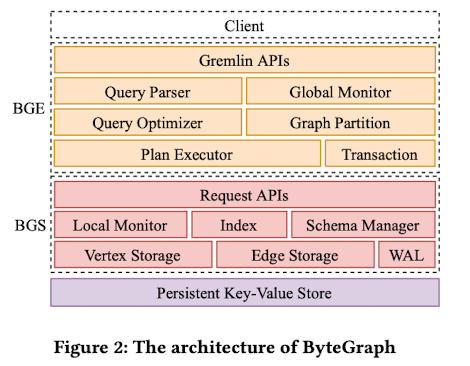
- BGE, ByteGraph Execution Engine 负责执行 SQL 语句。
- BGS, A cache layer in ByteGraph,负责存储相关。
- 底层的 KV Stroage 可以选用 RocksDB 或者 TerarkDB。
BGE 使用了 Gremlin 作为解析 query language 的解析器,这是一个专门用于图查询的工具。用户输入的查询语句经过 Gremlin 生成 execution plan 然后传给 BGE。
既然是查询引起,那么就涉及到分布式事务,BGE也是用了 2PC。
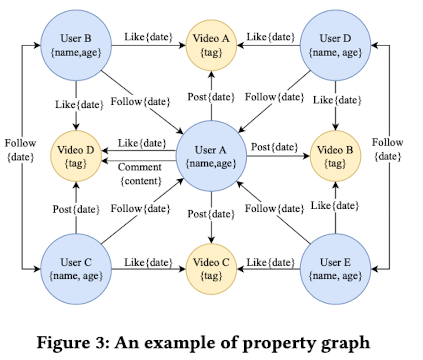
上图可以直观的显示 ByteGraph 数据库中所存的数据,可见 KV store 是比较适合存这类数据的,因此 BG 的最底层是 KV store。
实现
5.1 分布式事务处理
前面提到,分布式事务处理用的是 2PC。值得一提的是,BG 不支持 MVCC
5.2 高可用和容错
如果一台 BGS 挂了,BGE 收不到心跳信息以后,就会把 request 转发给 hash ring 上的下一个 BGS。没错,这里也用到了一致性 hash,并且了一个改进版本的 weighted consistent hashing algorithm。
与 Spanner 用原子钟不同,ByteGraph 没有财大气粗到用这么高端的东西,BG 用了 Hybrid Logic Clock (HLC) 来避免 clock skew。 在 OceanBase 论文中,没有明确说 OB 用了那种 logic clock,但是在 7.2 节中提到了 cockroachDB 也是用的 HLC。
在记录 log 上,BG 使用了 WAL 的方式。
OceanBase
文章开篇就讲了 OceanBase 的特点: Multi-Tenant, Shared-Nothing, 可以部署 on-premise 或者 off-premise, 同时有 SQL 查询,是一个 HAP 性数据库。
整个系统设计分一下几个方面
架构
可以跨 region 多个 zone,每一个 数据库表都被 partition 为多个小的表,这样能存到不同 region/zone 的节点上,而且每个 partition 都有副本 replica。这些副本用 Paxos 算法管理。
SQL Engine
解析用户输入的 SQL 语句总是耗时的,因此 OB 用了一个轻量级的框架做词法分析,然后取 cache 中匹配,如果匹配到了就不需要做后续的语法分析、生成 exection plan 等步骤了。
说白了,还是用 cache 空间换时间。
Multi Tenancy
一个系统级 tenant,其他的都是普通 tenant。
资源隔离在概念上类似 Docker 和 VM,但 OB 是自己做的。 OB 做到 CPU、内存、数据结构(SQL exection plan 的 cache)、transaction 相关的结构 的隔离。
Storage Engine
基于 LSM Tree,但是在做 Daily Incremental Major Compaction 等方面做了优化,这部分看的不是很懂,应该与 LSM 的一些原理相关。
Transaction
无外乎就是两阶段提交 2PC,但是 OB 基于 2PC 设计了自己的 OceanBase 2PC。
除以上外,还有 Isolation Level 和 Replicated Table 部分,这部分也不是很懂。
Lessons In Building OceanBase
这个是本文最有意思的部分,提到了 OB 发展将近 10 年之间的一些演变,同时还对比了一些流行的分布式数据库。
我的总结
论文在技术、架构上只是提纲挈领,无法涉及更多的细节,看下来感觉数据库系统就是这么设计的,大同小异,无外乎就是 Raft、Paxos、2PC、LSM,ACID、MVCC、Isolation Level、WAL、HLC。
但是同时也觉得自己在这方面的积累不够,比如 LSM tree,虽然各家数据库都用了,但是每家在阐述自己的优化时,就读的云里雾里。
另一方面,感觉很多概念 DDIA 这本书里也看了,但是在论文中看到这些概念时,还是不了解他们在一个数据库系统中起的作用,比如 2PC,Isolation Level,看来再读一遍 DDIA 还是很有必要。