关于 bbolt 的分析,网上已经有很多资料,本文只是对资料和源码的整理,主要是自己的学习笔记,文章最后的参考资料中有更多链接。
bbolt DB 整体组织
首先,bbolt 的一个文件是一个 DB,DB 中可以有多个 table, 每一个 table 是一个 B+ 树。而这个 table 在源码中就是 bucket, 整个 DB 就是一个大 bucket,它的子节点有多个 bucket。整体结构如图所示:
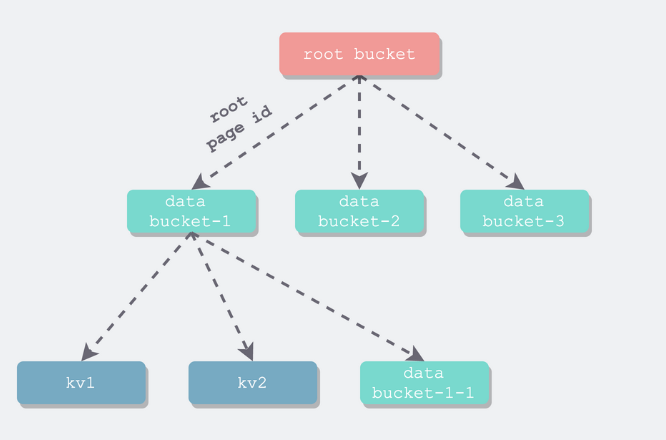
- 顶层 B+ 树,比较特殊,称为 root bucket,其所有叶子节点保存的都是子 bucket B+ 树根的 page id
- 其他 B+ 树,不妨称之为 data bucket,其叶子节点可能是正常用户数据,也可能是子 bucket B+ 树根的 page id。
这样,就清楚的知道了 bbolt 中 DB,table,和 data 是如何组织的了。
bbolt 的源码很简洁,主要功能分布在以下几个文件:
- bucket.go:对 bucket 操作的高层封装。包括 kv 的增删改查、子 bucket 的增删改查以及 B+ 树拆分和合并。
- node.go:对 node 所存元素和 node 间关系的相关操作。节点内所存元素的增删、加载和落盘,访问孩子兄弟元素、拆分与合并的详细逻辑。
- cursor.go:实现了类似迭代器的功能,可以在 B+ 树上的叶子节点上进行随意游走。
- page.go: page 是磁盘上一个 4kb 页的表示,注意,相比 page,第二行提到的 node 表示的是内存里的结构。
- db.go : bbolt 的主要源码
- tx.go : bbolt 实现 MMVC 的主要代码。
如何加载文件到内存,成为一个DB?
假设有一个数据库文件 data,那么bbolt 的源码是如何读取这个文件,并且在在内存建立DB的呢?
这就要先看看 data 文件在磁盘上是如何组织的了:

由此可见,data 文件中最开始的三个页面存的都是管理信息,之后是 branch 和 leaf page,branch是 B+树的中间节点,leaf 是叶子结点。
Page 页结构
前面提到 page 结构体是磁盘页面的表示,因此第一个出场的是 page 结构体
type page struct {
id pgid
flags uint16
count uint16 // 页面中存储的数据数量,仅在页面类型是branch以及leaf的时候起作用
overflow uint32
}

boltdb 直接将 page 结构体的二进制格式写入文件,避免了序列化和反序列化的开销:
写的时候直接将需要写入的结构体转换为 byte 数组写入文件:
ptr := (*[maxAllocSize]byte)(unsafe.Pointer(p))
从磁盘读取的时候,也是直接强制类型转换
func (db *DB) page(id pgid) *page {
pos := id * pgid(db.pageSize)
return (*page)(unsafe.Pointer(&db.data[pos]))
}
node 结构
前面提到,page 是磁盘一个页的表示,但是在 bbolt 中,page 并不是 B+ 树上的节点,B+ 树节点使用 node 结构体表示的,访问结点时,首先要将 page 反序列化后得到得到 node 结构体,
// node represents an in-memory, deserialized page.
type node struct {
bucket *Bucket // 该node所属的bucket指针
isLeaf bool
unbalanced bool
spilled bool
key []byte // 保存 inodes[0].key , node.read()
pgid pgid // 当前node在mmap内存中相应的页id
parent *node
children nodes // 保存已实例化的孩子节点的node,用于spill时递归向下更新node,
// 已实例化,指已经从文件的 page load 到了 内存里
inodes inodes // 对于分支节点是 key+pgid 数组,对于叶子节点是 kv 数组
}
type inode struct {
// 共有变量
flags uint32
key []byte
// 分支节点使用
pgid pgid // 指向的分支/叶子节点的 page id
// 叶子节点使用
value []byte // 叶子节点所存的数据
}
node 和 page 的相互转换通过 node.read(p *page) 和 node.write(p *page) 实现。
meta 页结构
page 页结构是其他页结构的基础,其他的页,比如 meta,freelist 都是从 ptr 指针的位置开始的。
type meta struct {
magic uint32
version uint32
pageSize uint32 // boltdb文件的页面大小
flags uint32 // 保留字段,暂时未使用
root bucket // 保存boltdb的根bucket的信息
freelist pgid // 保存freelist页面的页面ID
pgid pgid // 保存当前总的页面数量,即最大页面号加一
txid txid // 上一次写数据库的事务ID,可以看作是当前boltdb的修改版本号,每次写数据库时加1,只读时不改变。
checksum uint64
}
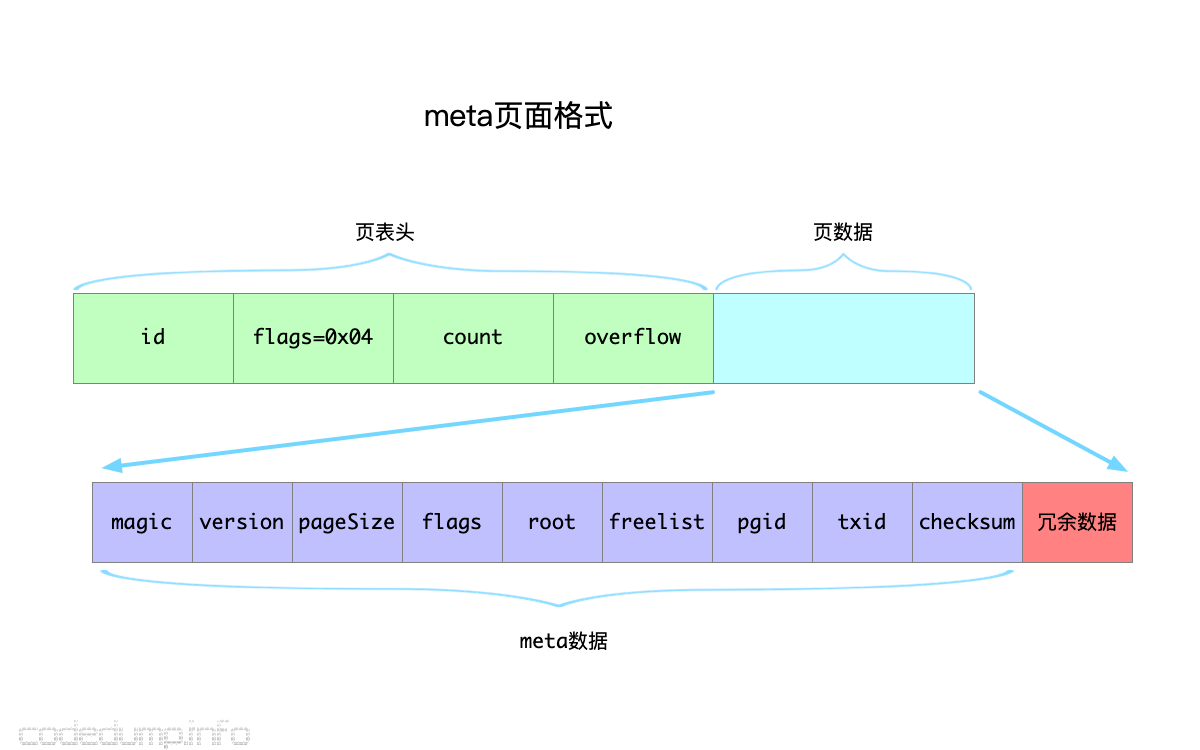
freelist 页面
type freelist struct {
ids []pgid // 保存当前闲置页面id的数组。
pending map[txid][]pgid // 保存事务操作对应的页面ID,键为事务ID,值为页面ID数组。这部分的页面ID,在事务操作完成之后即被释放。
cache map[pgid]bool //标记一个页面ID可用,即这个成员中的所有键都是页面ID,而这些页面ID当前都是闲置可分配使用的。
}
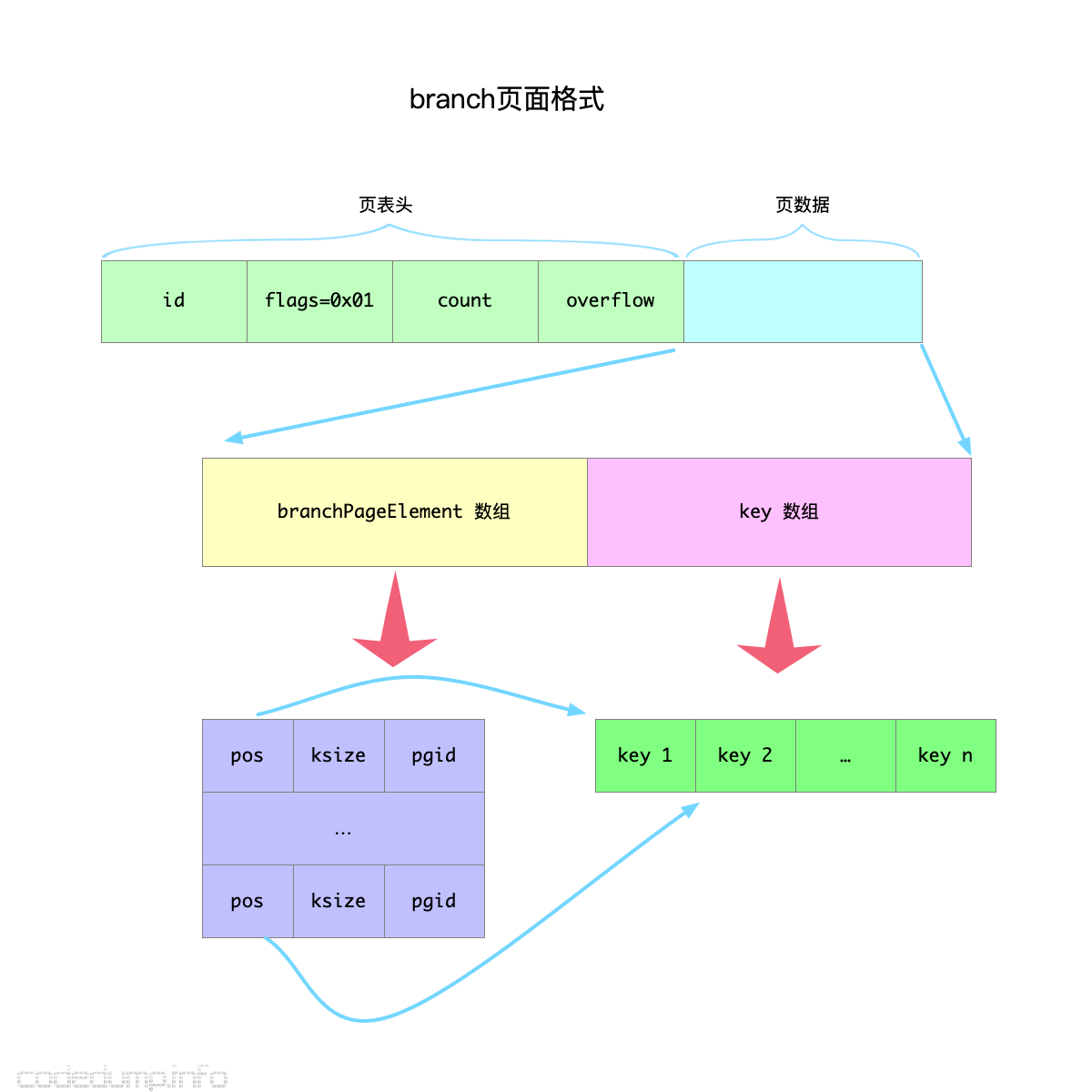
branch 页面
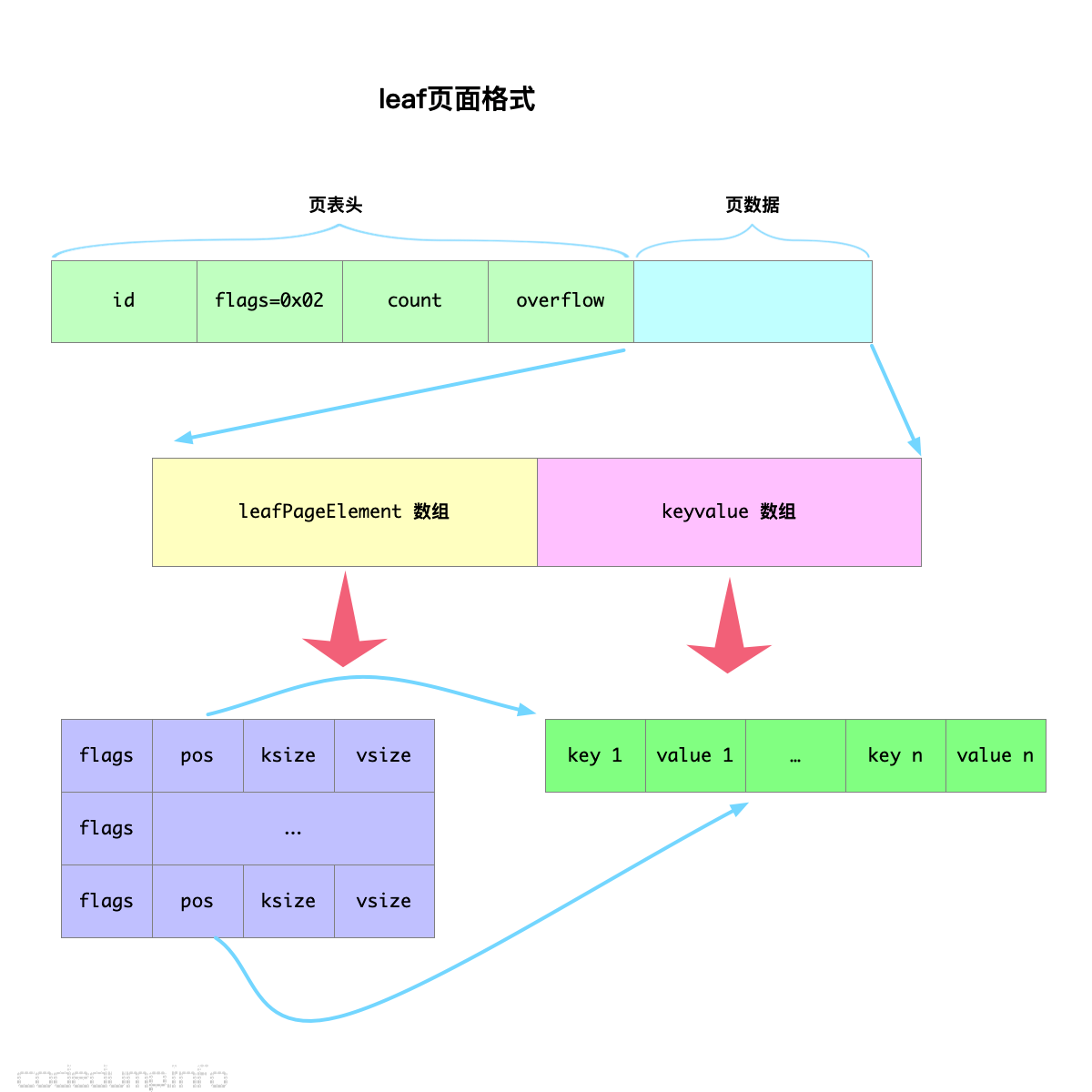
leaf 页面
打开一个 data file
上面介绍了基本的几种数据结构,接下来就跟着源码看看打开 data file的流程。
首先,用户调用 bolt.Open() 函数打开一个 data.db 文件,
Open 函数內部调用 DB.mmap() 函数,作用是把 data.db 文件作为内存映射
func (db *DB) mmap(minsz int) error {
// Memory-map the data file as a byte slice.
if err := mmap(db, size); err != nil {
return err
}
// Save references to the meta pages.
db.meta0 = db.page(0).meta()
db.meta1 = db.page(1).meta()
}
func mmap(db *DB, sz int) error {
// Map the data file to memory.
b, err := syscall.Mmap()
// Save the original byte slice and convert to a byte array pointer.
db.dataref = b
db.data = (*[maxMapSize]byte)(unsafe.Pointer(&b[0]))
db.datasz = sz
return nil
}
这样 db.data 就代表了这个 data 文件的起始位置,因此可以直接获取 db.meta0, meta1 了。
最后,在 DB.Open() 函数的末尾,再调用一下 loadFreelist(), 整个打开 data.db 文件的过程就结束了,此时内存里已经有了一个 bbolt 数据库。
为什么要loadFreelist 呢? 因为一个数据库文件里面有的页可能是分配了没有用的,所以在数据库启动时,需要load free 的页面。
Cursor 的实现
cursor 实现了一个游标功能,从结构体定义可以看出,cursor 是作用在一个 bucket 上的
type Cursor struct {
bucket *Bucket
stack []elemRef
}
type elemRef struct {
page *page
node *node
index int // 保存在当前page、node遍历到了哪个节点
}
其中 elemRef 用于纪录遍历时经过的节点,但是为什么同时有 page 和 node 的指针呢?
因为 bbolt 实现了 lazy load page 的策略,也就是说当访问一个B+ 树节点 node 的时候,很可能这个节点还不再内存,因此需要直接从 page 结构里读取。听起来有点像 OS 里缺页调用的感觉。
cursor 的实现在 cursor.go 文件中,主要提供了一下几个函数
- First:返回当前Bucket的第一个数据。
- Last:返回当前Bucket的最后一个数据。
- Next:返回当前游标位置的下一个数据。
- Prev:返回当前游标位置的上一个数据。
- Seek:查找到对应的叶子节点返回其键、值。
- keyValue:返回当前游标位置的键、值、标志位。
- Delete:删除当前游标位置的数据。
Frist() 和 Last()
先从最简单的 First() 函数看起,如何找一个 B+ 树的第一个元素? B+ 树的性质决定所有的叶子结点,从左到右是有序的,因此 First 就是最左叶子结点的第一个元素
所以,从源码上来看就是不断的读取 branch 结点第一个元素,知道遇到 leaf 结点为止的过程
func (c *Cursor) first() {
for {
// Exit when we hit a leaf page.
var ref = &c.stack[len(c.stack)-1]
if ref.isLeaf() {
break
}
// Keep adding pages pointing to the first element to the stack.
var pgid pgid
if ref.node != nil {
pgid = ref.node.inodes[ref.index].pgid
} else {
pgid = ref.page.branchPageElement(uint16(ref.index)).pgid
}
p, n := c.bucket.pageNode(pgid)
c.stack = append(c.stack, elemRef{page: p, node: n, index: 0})
}
}
// last moves the cursor to the last leaf element under the last page in the stack.
func (c *Cursor) last() {
for {
// Exit when we hit a leaf page.
ref := &c.stack[len(c.stack)-1]
if ref.isLeaf() {
break
}
// Keep adding pages pointing to the last element in the stack.
var pgid pgid
if ref.node != nil {
pgid = ref.node.inodes[ref.index].pgid
} else {
pgid = ref.page.branchPageElement(uint16(ref.index)).pgid
}
p, n := c.bucket.pageNode(pgid)
var nextRef = elemRef{page: p, node: n}
nextRef.index = nextRef.count() - 1
c.stack = append(c.stack, nextRef)
}
}
注意对比一下 first 和 last 的逻辑,区别仅仅是在于最后三行,一个是 0, 一个是 n。
Next()
返回当前游标位置的下一个数据。略
bbolt 如何实现 MVCC
MVCC(Multiversion concurrency control,多版本并发控制)的做法是:保存数据库中的多个版本,修改的是一个版本,而同时进行的读操作读取到的数据是旧版本的数据,这样即便读到了旧的数据也不影响,只要不是写到一半的脏数据就好。
bbolt 实现 MVCC 的关键是 两个 meta 页的设计:
- 首先,每个事务都是有递增的 txid,
- meta0 和 meta1 各储存一个 txid,假设是 10 和 11, txid 大的代表信息是最新的,读操作选取 txid 大的 meta 页作为信息来源,可以实现并发读。
- 写事务开始时, 拷贝 txid 大的 meta1,并给一个更大的 txid=12,在事务结束后写入 meta txid=10 的页面,即 覆盖旧的 meta 页
- 在写事务的过程中,任何数据被修改,都在commit 的时候被写入新的页面,假设修改了原来 [6,7,8] 的内容,那么 commit 的时候,整个页面的数据都写入 [ 9,20,21],同时 [6,7,8] 保持不变,这样读操作依然可以读到旧数据。
- 写事务最后 commit 完成,把 meta txid = 10 的更新为 txid = 12, 因此,后续读操作都选择这个最新的 meta 信息。