论文原文链接 In Search of an Understandable Consensus Algorithm
Raft 保证一致性的 4 个重要组成部分: 领导人的选举,日志复制,安全性,集群成员的变化。
Raft 是一个强领导者算法,意思就是所有的数据以当前领导者(Leader)上的为准,领导者上有的就是正确的,领导者上没有的就是错误的。
5.1 Raft 的基本术语和概念
任期的概念:任期(term) 用来区分时间轴上不同的领导者,当领导者换了,日期也也立刻变更。raft 算法用 term 来表示一个 逻辑时钟,而不是用传统的几月几日几点几分几秒,term 是一个递增的整数,当领导者变了,term 也 +1。
集群中的每一个服务器都存储了一个 currentTerm,任意两个 server 要相互通信时都需要包含各自的 currentTerm。如果一个 server 的 currentTerm 值小于对方,那么它需要更新自己的值。如果 candidate 或者 leader 发现他们自己的 currentTerm 比其他人的要小,那个立马变成 follower。如果收到的请求包含一个旧的 currentTerm,直接忽略。
原论文的图 2 包含了大量的信息,我自己制作了下面四个图片。
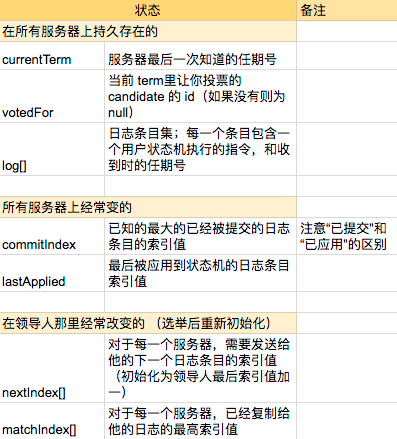
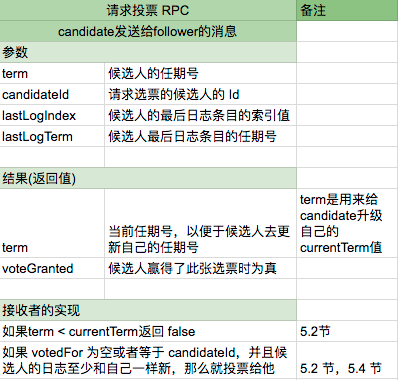
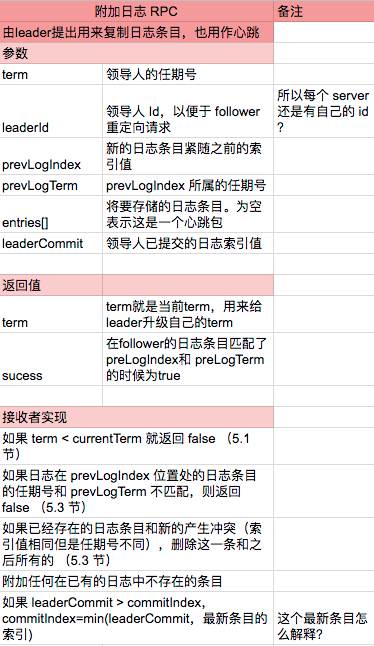
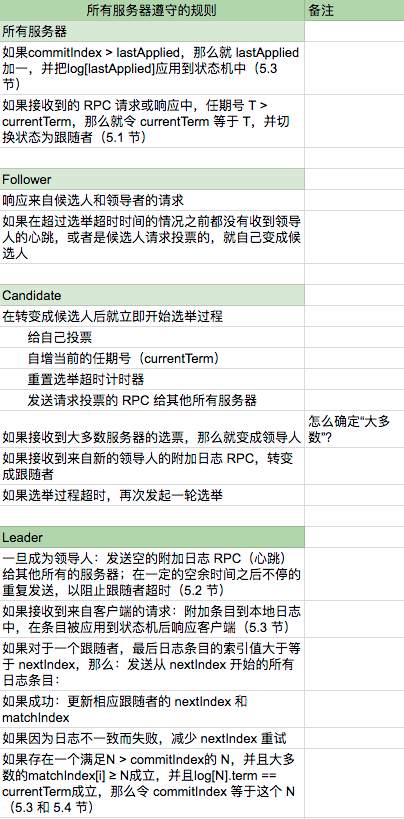
5.2 领导人的选举
领导人不断的向集群中其他人发送心跳包,当集群中一个 server 在一段时间里没有收到领导人的心跳包,那么他就要起义,自己竞选当领导人。
开始一次选举
Follower 把自己的 term+1,身份转变成 Candidate,向集群中其他 server 发起请求投票 RPC,当他获得大多数选票时,就成功当选。
问题:他怎么知道 “大多数” 是多少?(etcd 的实现似乎是每个 server 知道集群里面有多少台服务器)
在竞选的过程中, candidate 一直保持着 candidate 的身份直到下面三个事件中的任何一个发生:
- 它赢得了选举,成为 leader
- 其他人赢得了选举
- 一段时间过去了,没有人成为 leader (大家都在选举,没有人得票数过半),所以准备重新开始。
在一个特定的 term 内,server 只会给一个人投票,先来先到。也就是说,比如 term=100,serverA 投给了 B,那么它不会再投票给任何人,在下一个 term=101,他才可以继续投票。
在 candidate 发起了投票等待回应的过程中,它有可能会收到其他 server 发来的 AppendEntries RPC,(这个 RPC 只能是 leader 发,但是这个 server 认为自己是 leader),这时,candidate 比较 currentTerm,如果比自己的大,就认输了,如果比自己的小,直接拒绝。
5.3 日志复制
当 follower 和 leader 的日志出现不一致时,以 leader 上的信息为准。follower 首先需要找到自己 logs 中与 leader 一致的最后的地方,然后从那个地方开始,把后面的 log 全部抹掉,复制 leader 的日志。这个过程发生在 AppendEntries RPC 的过程中。
leader 为每个 follower 维护一个 nextIndex,表示leader 给这个 follower 发送下一条 logs 的 Index。
当一个服务器赢得选举成为了 leader 之后,它初始化所有的 nextIndex 为 leader 最新的 log index + 1,如果一个 follower 的 log 和 leader 不一致,那么在下一次的 AppendEntries RPC 中,AppendEntries 一致性检查函数将返回 false。(一致性检查函数发现了不一致时,会自动删除掉 follower 上不一致的日志)
当 leader 收到了AppendEntries RPC 返回 false,那么它知道日志出现了不一致,然后减少 nextIndex 的值,再次发送 RPC 尝试,直到成功为止。成功的时候的 nextIndex 值就是他们日志一致的地方,然后开始复制。
5.4 安全性
Raft 通过比较两份日志中最后一条日志条目的索引值和任期号定义谁的日志比较新。
- 如果两份日志最后的条目的任期号不同,那么任期号大的日志更加新。
- 如果两份日志最后的条目任期号相同,那么日志 index 大的那个就更加新。
通过这样的2个条件,选举出一个包含所有过半提交日志的server来作为leader,但是这样的比较规则有一个缺陷,论文作者用了下面这张图来说明问题。
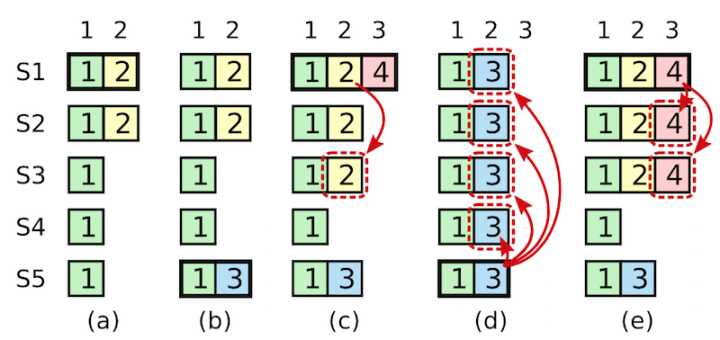
图 8:如图的时间序列展示了为什么领导人无法通过老的日志的任期号来判断其提交状态。在 (a) 中,S1 是领导者,部分的复制了索引位置 2 的日志条目。在 (b) 中,S1 崩溃了,然后 S5 在任期 3 里通过 S3、S4 和自己的选票赢得选举,然后从客户端接收了一条不一样的日志条目放在了索引 2 处。然后到 (c),S5 又崩溃了;S1 重新启动,选举成功,开始复制日志。在这时,来自任期 2 的那条日志已经被复制到了集群中的大多数机器上,但是还没有被提交。如果 S1 在 (d) 中又崩溃了,S5 可以重新被选举成功(通过来自 S2,S3 和 S4 的选票),然后覆盖了他们在索引 2 处的日志。但是,在崩溃之前,如果 S1 在自己的任期里复制了日志条目到大多数机器上,如 (e) 中,然后这个条目就会被提交(S5 就不可能选举成功)。 在这个时候,之前的所有日志就会被正常提交处理。
粗看这张图似乎很难理解在什么条件下这套机制会出错,后来在网上搜索了一下,觉得下面这个回答更加易懂[2]。
按照上述选举方式,如果大家term都一样则选举出来的leader必然包含所有过半提交日志,但是如果term不一样,则按照上述选举方式选出来的leader可能并没有包含所有过半提交的日志。所以说这种选举PK的方式中的条件1是存在缺陷的,如何来解决呢?解决办法的本质就是消除条件1可能导致的误判,在条件2下进行PK选举。
Raft的解决方式:那么就需要对过半提交加以限制,多加一个条件即当前term不会提交之前的term的日志条目。一旦加上了这个限制意味着含有所有过半提交的日志的几个server必然拥有目前最大的term,这样的话再次进行leader选举时,就避免了条件1的误判,在条件2下进行PK