投票的过程
日志的复制
一旦选举成功,所有的 Client 请求最终都会交给 Leader 处理。
当 Client 请求到 Leader后,Leader 首先将该请求转化成 LogEntry,然后添加到自己的 log[] 中,并且把对应的 index 值存到 LogEntry 的 index 中,这样 LogEntry 中就包含了当前 Leader 的 term 信息和在 log[] 中的index信息,这两个信息在发给 Follower 以后会用到。
所以一旦一个节点成为 Leader 以后,那么它的 log[] 保存的这一组 LogEntry 就代表了整个集群中的最终一致的数据。用 raft 论文的话来说就是,节点是一个状态机,LogEntry 是指令集,任何一个节点,只要逐个执行这一串指令,最后状态机的状态都一样。
先看看与日志复制相关的几个数据结构,首先是 raft 结构,其中相关的有以下几个变量:
type Raft struct {
....
log []LogEntry
commitIndex int // 所有机器
lastApplied int
nextIndex []int // 只在 leader
matchIndex []int
.....
}
nextIndex 和 matchIndex,这两个数组只有当这个 raft 是 Leader 的时候才有效,否则这两个数组的内容无效。
对于 leader 来说,它要为集群中的每个 follower 保存2个属性,一个是 nextIndex,即 leader 要发给该 follower 的下一个 entry 的 index,另一个就是 matchIndex 即 follower 发给 leader 的确认index。
一个leader在刚开始的时候会初始化:
for (all) {
nextIndex[x] = leader 的 log 的最大 index+1
matchIndex[x] = 0
}
 {:height=“200” width=“400”}
{:height=“200” width=“400”}
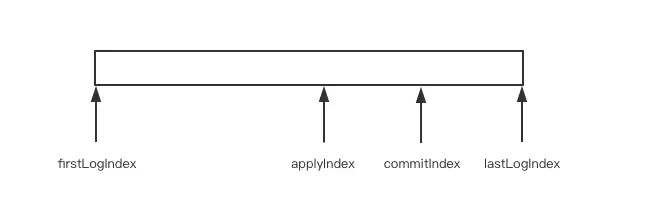
- firstLogIndex/lastLogIndex 标识当前日志序列的起始位置。
- commitIndex 表示当前已经提交的日志,也就是成功同步到集群中日志的最大值。
- applyIndex 是已经 apply 到状态机的日志索引,它的值必须小于等于 commitIndex,因为只有已经提交的日志才可以 apply 到状态机。
type AppendEntriesRequest struct {
Term int32
LeaderID int
PrevLogIndex int
PrevLogTerm int32
Entries []LogEntry
LeaderCommit int
}
Leader 准备 AppendEntries RPC 请求的参数,其中:
1)prevLogIndex = nextIndex-1。
2)prevLogTerm = 从 log 中得到上述 prevLogIndex 对应的 term。
3)entries = leader 的 log 的 prevLogIndex+1 开始到 lastLog,此时是空的。
4)leaderCommit = commitIndex
follower 接收到 AppendEntriesRequest 请求之后,回复给 leader 一个 AppendEntriesReply 结构,定义如下:
type AppendEntriesReply struct {
Term int32
Success bool
ConflictIndex int
ConflictTerm int32
}
在回复之前,先做如下几项检查:
1)重置 HeartbeatTimeout
2)发来请求的 term 和自己当前的 term,若发来的小,则直接返回 false
3)检查 prevLogIndex 和 prevLogTerm 和自己当前 log 对应的 index 的 log 是否一致。这里可能会有不一致,因为初始 prevLogIndex 和 prevLogTerm 是 leader 上的 lastLog,不一致的话返回 false,同时将自己的log的 lastIndex 传送给 leader。
4)leader 接收到上述 false 之后,会记录该 follower 的上述 lastIndex
macthIndex = 上述lastIndex
nextIndex = 上述lastIndex+1
然后 leader 会重新发送新的 prevLogIndex、prevLogTerm、和 entries 数组
5)follower 检查 prevLogIndex 和 prevLogTerm 和对应 index 的 log 是否一致(假设一致了)
6)follower 于是开始将 entries 中的数据全部覆盖到本地对应的 index上,与 leader 保持一致。
7)follower 将最后复制的 index 发给 leader,leader 用来更新 macthIndex[] 中对应这个 follower 的项。
leader 一旦发现有些 entries 已经被过半的 follower 复制了,就将该 entry “提交”,将 commitIndex 提升至该 entry 的 index。(这里是按照 entry 的 index 先后顺序提交的),具体的实现可以通过 follower 发送过来 macthIndex 来判定是否过半了。
一旦可以提交了,leader 就将该 entry 应用到状态机中,然后给客户端回复 OK。然后在下一次 heartBeat 心跳中,将 commitIndex 传给了所有的 follower,对应的 follower 就可以将 commitIndex 以及之前的 entry 应用到各自的状态机中了。
TestRejoin2B 测试
raft server 在向测试主程序确认 101,103 已经 apply 了以后,无论后面的 leader 变化成谁,leader 再向 applyCh channel 提交信息的时候,log 前两项必须是 101,103,否则测试主程序会报错。